Wie intelligent sind ChatGPT und Large Language Models (LLM)?
geschrieben_von
_upscale_zoom-120.jpg)
categories
ChatGPT, Google Bard, Bing Chat, LLaMA von Meta – Sprachmodelle sind in der breiten Bevölkerung angekommen. Auch Swico befasst sich intensiv mit dieser Entwicklung. Wie funktionieren LLM und Chat-Assistenten grundsätzlich und wo sind die Potentiale und Risiken?

Die Swico Interessengruppe (IG) ICT Business & Innovation hat sich an ihrer letzten Sitzung mit diesen und weiteren Fragen auseinandergesetzt: ChatGPT & LLM – stochastische Papageien oder auf dem Weg zu menschenähnlicher Intelligenz? Welche Anwendungsfälle gibt es im Alltag?
Christian Schwarzer, AI-Experte und Gründer der Kortikal AG, klärt auf.
ChatGPT generiert Texte schrittweise basierend auf der gelernten Wahrscheinlichkeitsverteilung für das nächste Wort. "Das klingt plausibel, ist aber nicht zwingend inhaltlich korrekt», erläutert Christian Schwarzer, bevor er mit den Basics beginnt. Die folgenden Begriffe werden zwar häufig gleichbedeutend verwendet, sollten aber eigentlich unterschieden werden:
- Artificial Intelligence (AI) steht für alle Arten von Technologien, die Systeme oder Agenten mit intelligentem Verhalten ausstatten. Unter intelligentem Verhalten wird dabei Planung, Begründung, Entscheidfällung und Lernen verstanden.
- Machine Learning (ML) steht für Systeme, die basierend auf Daten lernen. Statt einem Computer explizit die Anweisungen in Form eines Algorithmus vorzugeben, werden die Parameter eines Modells mittels Trainingsdaten und einer Optimierungsmethode gelernt.
- Neuronale Netzwerke (NN) ist die aktuell am weitesten verbreiteste ML-Methode. Deep Learning (die Nutzung von neuronalen Netzwerk-Architekturen mit sehr vielen Schichten und Parametern) ist die Basis des Erfolgs von ChatGPT.
Die mathematischen Tiefen eines Deep Neural Networks
Ein neuronales Netzwerk ist gemäss nachfolgender Abbildung ein «universeller Funktionsapproximator», der beliebige Zusammenhänge zwischen Daten-Inputs und -Outputs lernen kann. Das neuronale Netzwerk besteht grundsätzlich nur aus vielen einfachen Recheneinheiten mit Gewichtsparametern, die während des Trainingprozesses laufend angepasst werden. Dies geschieht solange, bis die Vorhersage des Netzwerks möglichst gut mit den in den Trainingsdaten vorgegbenen Outputs übereinstimmt.
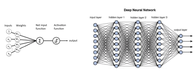
Als Datenbasis für das Training eines Sprachmodells werden grosse Mengen an Textdaten aus dem Internet verwendet: z.B. CommonCrawl, Github, Wikipedia, ArXiv, StackExchange etc.
Durch «Tokenisierung und Embedding» werden die Wörter aus den Texten aus den Datenquellen in Vektoren bestehend aus Gleitkommazahlen umgewandelt. Denn neuronale Netze arbeiten nicht mit Wörtern und Buchstaben, sondern nur mit Zahlen.
Die unterschiedlichen Sprachmodelle basieren auf Varianten der sogenannten Transformer-Architektur und lernen im Trainingsprozess das wahrscheinlichste nächste Wort vorherzusagen, indem sie eine Wahrscheinlichkeitsverteilung über alle möglichen Wörter im Vokabular generieren.

Ein trainiertes Sprachmodell könnte z.B. für den Satzanfang «She said, I never….» die in Grafik 2 gezeigten Wahrscheinlichkeiten für das nächste plausible Wort generieren. Bei der eigentlichen Generierung des nächsten Wortes kann der Benutzer mit verschiedenen Parametern steuern, wie die Wörter von dieser Wahrscheinlichkeitsverteilung gezogen werden sollen.
Um ausgehend von einem generischen Sprachmodell ein dialog-fähiges Chat-Assistenz-Modell zu entwickeln, sind noch weitere Trainingsschritte nötig. Dieses «Finetuning» geschieht in der Regel durch Verwendung von sehr vielen von Menschen erzeugten Frage-Antwort Beispielen. Für ChatGTP wurde zudem noch ein separates Reward-Model trainiert mit dem mittels Reinforcement Learning das Sprachmodell noch weiter verbessert wird.
Unterschiedliche LLM Assistenten: Evolutionsbaum
Obwohl in der öffentlichen Diskussion fast ausschliesslich von ChatGPT gesprochen wird, existieren viele weitere Sprachmodelle und Chat-Assistenten von verschiedenen Organisationen. Nur ein kleiner Teil davon sind echte Open Source Projekte wie z.B. open-assitant.io. Die meisten Modelle sind nur über eine Schnittstelle (API) zugänglich.
Was können LLM Systeme wirklich?
Vereinfacht gesagt, lernen diese Modelle Statistiken basierend auf Wortfolgen. Sie können keine selbstständigen Überlegungen anstellen oder eine Antwort planen. Bei den Antworten wird kein Ziel oder Zweck verfolgt, abgesehen von der Vorhersage des plausibelsten nächsten Wortes. Auch gibt es bei Antworten aktuell keine Püfung, ob eine Aussage inhaltlich korrekt ist. Selbst unter AI-Forschern ist umstritten, ob diesen Modellen «Intelligenz» zugesprochen werden kann und ob sie «verstehen» können.
Problematisch in der Nutzung ist, dass Menschen vom fliessenden und gekonnten Sprachausdruck dieser Systeme beeindruckt sind und daraus auf menschenähnliche Intelligenz und Gedankenprozesse schliessen.
Während Weltuntergangsszenarien, welche durch KI ausgelöst würden, eher weit hergeholt sind, stellen sich aktuell brisantere Fragen:
- Transparenz der Anbieter bzgl. verwendeter Trainingsdaten
- Nutzung der Prompts von Anwendern
- kritischer Umgang mit künstlich generierten Inhalten
- Plausibilität des Wahrheitsgehaltes
Für was können LLM heute eingesetzt werden?
- Schreibassistenz: Ob als Inspirationsquelle, um einen Entwurf zu erstellen, den Schreibstil aufzubessern oder für die Erstellung einer Zusammenfassung.
- Assistenz in der Software-Entwicklung (z.B. GitHub Co-Pilot)
Stets im Hinterkopf behalten sollten Anwenderinnen und Anwender, dass diese Modelle «halluzinieren» und somit falsche oder inkonsistente Antworten liefern können. Zudem verfügen Systeme längst nicht immer über die aktuellsten Informationen, weil Wissenslücken bestehen. Letztlich fehlt es den Systemen an der Fähigkeit, menschenähnlich logisch zu denken, da die Antworten rein durch die iterative Vorhersage des nächsten Wortes entstehen.
Swico Interessengruppe (IG) ICT Business & Innovation
Diese Swico Arbeitsgruppe fokussiert sich auf die aktuellen Entwicklungen der ICT-Branche und deren Auswirkungen auf End-to-End Geschäftsmodelle. Besetzt ist die IG mit Beiräten aus unterschiedlichen Sub-Branchen, damit die neuen Trends umfassend aufgespürt und gewürdigt werden können.
